arXiv · Apr 2026 · NVIDIA · TensorRT-LLM · Sparse Attention
GVR Top-K
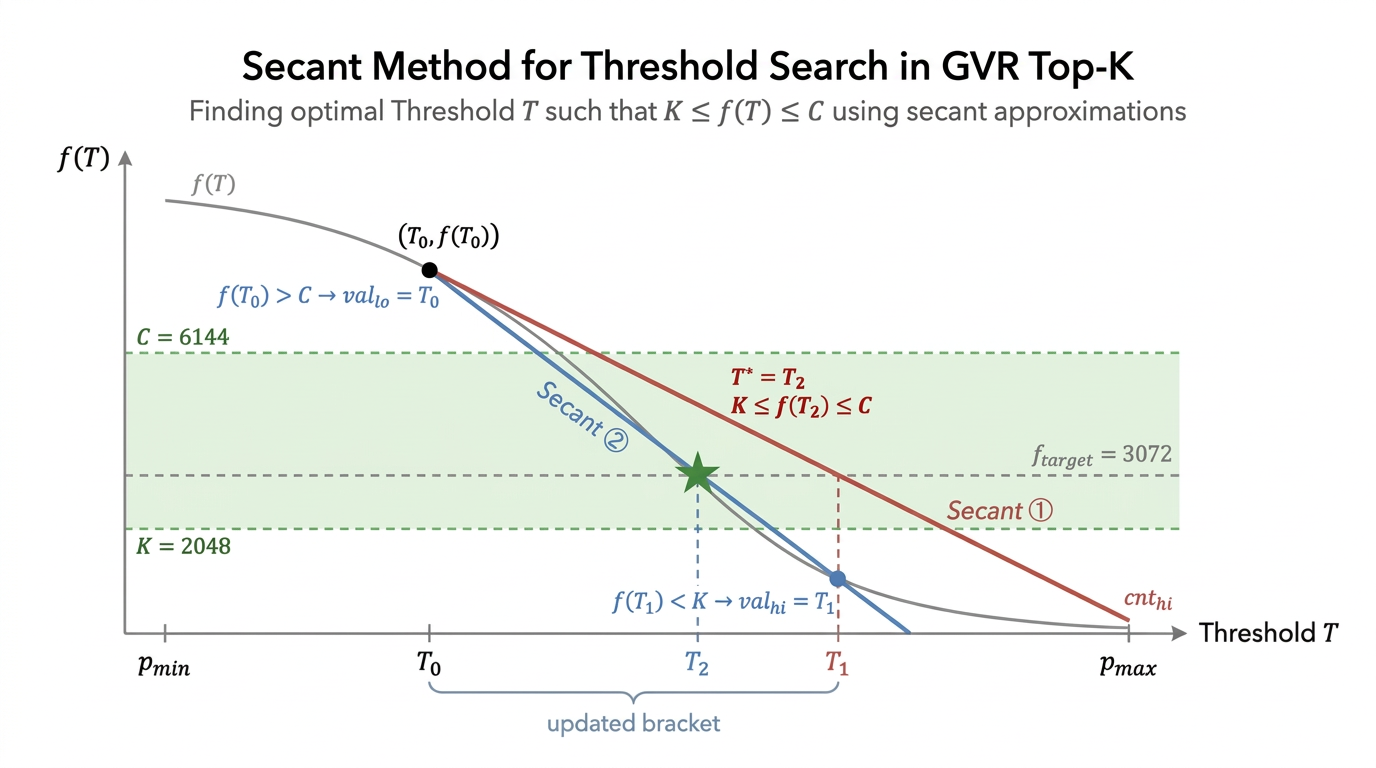
Innovation Temporal-correlation threshold search predicts compact candidate sets losslessly.
Impact 1.88x avg Top-K speedup; up to 9.3% generation gain; default DSv4 indexer path.
Evidence TensorRT-LLM PRs, NVIDIA tech blog, arXiv paper, three filed patents.
Technical formula
\[
f(T)=\left|\{\,i\mid x_i\ge T\,\}\right|,
\qquad K\le f(T^\ast)\le C
\]
\[
T_{\mathrm{new}}
=T_{\mathrm{lo}}+
\frac{f(T_{\mathrm{lo}})-f_{\mathrm{target}}}
{f(T_{\mathrm{lo}})-f(T_{\mathrm{hi}})}
\left(T_{\mathrm{hi}}-T_{\mathrm{lo}}\right)
\]
Lossless Top-K
1.88x avg Top-K speedup
Default DSv4 indexer Top-K